
Лучшие Программы для Оптимизации
 Эти статьи предназначены для разработчиков среднего уровня. Предполагается, что читатель стремится оптимизировать производительность программ с помощью распространенных возможностей программирования на языках C++ и Fortran*. Использование ассемблера и встроенных функций мы оставляем более опытным пользователям. Автор рекомендует желающим получить более подробные материалы, чтобы ознакомиться с архитектурой наборов инструкций процессоров и с многочисленными исследовательскими журналами, в которых публикуются великолепные статьи по анализу и проектированию структур данных.
Эти статьи предназначены для разработчиков среднего уровня. Предполагается, что читатель стремится оптимизировать производительность программ с помощью распространенных возможностей программирования на языках C++ и Fortran*. Использование ассемблера и встроенных функций мы оставляем более опытным пользователям. Автор рекомендует желающим получить более подробные материалы, чтобы ознакомиться с архитектурой наборов инструкций процессоров и с многочисленными исследовательскими журналами, в которых публикуются великолепные статьи по анализу и проектированию структур данных.
При приведении данных и кода в порядок используется два базовых принципа: нужно свести к минимуму перемещение данных и размещать данные как можно ближе к той области, в которой они будут использоваться. Когда данные попадают в регистр процессора (или как можно ближе к регистру), следует использовать их наиболее эффективно перед выведением из памяти или при отдалении от исполняемых блоков процессора.
Размещение данных
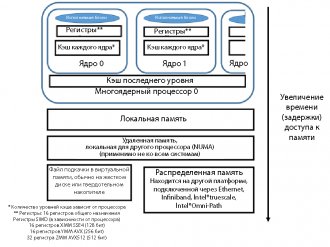
Рассмотрим три уровня, на которых могут находиться данные. Ближайшее место к исполняемым блокам — регистры процессора. Данные в регистрах можно обрабатывать: применять к ним умножение и сложение, использовать их в сравнениях и логических операциях. В многоядерном процессоре у каждого ядра обычно есть собственный кэш первого уровня (L1). Можно очень быстро перемещать данные из кэша первого уровня в регистр. Может быть несколько уровней кэша, но обычно кэш последнего уровня (LLC) является общим для всех ядер процессора. Устройство промежуточных уровней кэша различается для разных моделей процессоров; эти уровни могут быть как общими для всех ядер, так и отдельными для каждого ядра. На платформах Intel поддерживается согласованная работа кэша в пределах одной платформы (даже при наличии нескольких процессоров). Перемещение данных из кэша в регистр осуществляется быстрее, чем получение данных из основной памяти.
Данные в регистрах можно обрабатывать: применять к ним умножение и сложение, использовать их в сравнениях и логических операциях. В многоядерном процессоре у каждого ядра обычно есть собственный кэш первого уровня (L1). Можно очень быстро перемещать данные из кэша первого уровня в регистр. Может быть несколько уровней кэша, но обычно кэш последнего уровня (LLC) является общим для всех ядер процессора. Устройство промежуточных уровней кэша различается для разных моделей процессоров; эти уровни могут быть как общими для всех ядер, так и отдельными для каждого ядра. На платформах Intel поддерживается согласованная работа кэша в пределах одной платформы (даже при наличии нескольких процессоров). Перемещение данных из кэша в регистр осуществляется быстрее, чем получение данных из основной памяти.
 Схематическое расположение данных, близость к регистрам процессора и относительное время доступа показаны на рис. 1. Чем ближе блок находится к регистру, тем быстрее перемещение и тем короче задержка при поступлении данных в регистр для выполнения. Кэш — самая быстрая память с наименьшими задержками. Следующая по скорости — основная память. Может быть несколько уровней памяти, хотя о многоуровневом устройстве памяти мы поговорим во второй части этой статьи. Если страницы памяти размещаются в виртуальной памяти файла подкачки на жестком диске или твердотельном накопителе, скорость существенно снижается. Традиционная архитектура MPI с отправкой и получением данных по сети (Ethernet, Infiniband и т. д.) обладает большими задержками, чем получение данных в локальной системе. Скорость при перемещении данных из удаленной системы с доступом по MPI может различаться в зависимости от используемого способа подключения: Ethernet, Infiniband, Intel True Scale или Intel Omni Scale.
Схематическое расположение данных, близость к регистрам процессора и относительное время доступа показаны на рис. 1. Чем ближе блок находится к регистру, тем быстрее перемещение и тем короче задержка при поступлении данных в регистр для выполнения. Кэш — самая быстрая память с наименьшими задержками. Следующая по скорости — основная память. Может быть несколько уровней памяти, хотя о многоуровневом устройстве памяти мы поговорим во второй части этой статьи. Если страницы памяти размещаются в виртуальной памяти файла подкачки на жестком диске или твердотельном накопителе, скорость существенно снижается. Традиционная архитектура MPI с отправкой и получением данных по сети (Ethernet, Infiniband и т. д.) обладает большими задержками, чем получение данных в локальной системе. Скорость при перемещении данных из удаленной системы с доступом по MPI может различаться в зависимости от используемого способа подключения: Ethernet, Infiniband, Intel True Scale или Intel Omni Scale.
Видео на тему


Расказать о статье друзьям
Похожие статьи
Автоматическая Оптимизация Компьютера
Увеличение производительности компьютерных систем осуществляется сегодня, как правило, за счет физического параллелизма —…
Читать далее
Скачать Оптимизатор
Категория программы в каталоге программ : Связь, локальные сети Название: Описание: Оптимизатор батареи Айфона (iPhone)…
Читать далееПоследние статьи
-
 Программа Полной Оптимизации Компьютера Октябрь 25, 2023
Программа Полной Оптимизации Компьютера Октябрь 25, 2023 -
 Программы Очистки и Оптимизации Компьютера Торрент Октябрь 15, 2023
Программы Очистки и Оптимизации Компьютера Торрент Октябрь 15, 2023 -
 Оптимизация Работы Ноутбука Октябрь 5, 2023
Оптимизация Работы Ноутбука Октябрь 5, 2023 -
 Программа Автоматической Оптимизации Компьютера Сентябрь 25, 2023
Программа Автоматической Оптимизации Компьютера Сентябрь 25, 2023 -
 Утилита для Удаления Файлов Сентябрь 15, 2023
Утилита для Удаления Файлов Сентябрь 15, 2023 -
 Оптимизация Win 8 Сентябрь 5, 2023
Оптимизация Win 8 Сентябрь 5, 2023 -
 Удаление Программ из Реестра Август 26, 2023
Удаление Программ из Реестра Август 26, 2023 -
 Программы для Ускорения Работы Компьютера Август 16, 2023
Программы для Ускорения Работы Компьютера Август 16, 2023 -
 Программы Оптимизаторы Август 6, 2023
Программы Оптимизаторы Август 6, 2023